Motivation
Within any game that relies on fixed-recipe crafting mechanics, you need an efficient way to determine if a some pattern of items resolves to a known recipe. This is true of Minecraft and thus true of my PSXMC project. This problem is one that has been solved many times from naive to extremely efficient and implementation specific.
Context
Pattern matching for recipes could be seen as specic to the crafting medium (i.e. crafting table, furance, machines, etc) but this has the obvious problem of needing separate implementations per-medium which is way to much of a tradeoff for a Minecraft on a PS1. Especially if we want to allow for others to modify the game and add their own recipes and mediums.
In addition to this, we want to avoid, at any cost, the necessity to build the crafting recipes in memory at runtime. Remember the PS1 has at most 2MiB of memory to play with, so this is not a worthwhile consumption of that. Taking advantage of compile-time structuring and any optimisations that we can do therein would be ideal.
Requirements
Instead I'd like to build something general. So the set of requirements that need to be satisfied are:
- Compile-time generated recipe definitions
- Definable pattern size and dimensions
- Bounded complexity when traversing recipes at runtime
- Shaped and shapeless crafting adds no representational overhead
Implementation Approach
Before getting too heavy handed, it's important to do a bit of a literature review and analysis of existing approaches to know if a new algorithm is needed to solve these problems of whether it's possible to leech off someone else's hard work.
TLDR: Leech time.
Recipe Tree Encoding
Let's tackle the last three of the four requirements as they will argurably have more of an impact than the first. The first is also somewhat dictated by our approach here as well.
- Definable pattern size and dimensions
- Bounded complexity when traversing recipes at runtime
- Shaped and shapeless crafting adds no representational overhead
Structurally, what we want to do is be able to construct a tree that contains the minimum branch depth for any given recipe, where each node is a recipe ingredient. More specifically, for any recipe dimensions, we want to compute the quadralateral hull (smallest quad that surrounds the recipe), then for each of those nodes (in some order like top left to bottom right), string the recipe together as a set of nodes, each a child of the previous ingredient.
It turns out that this is already a thing, asked by David Eyk and answered by Jonathan Dickinson on the game development stack exchange: How could I implement something like Minecraft's crafting grid?
So let's just steal that and the example code written in C# for an example implementation.
This does almost exactly what was previously outlined. You take a recipe pattern with some dimensions that surround it. For example a line of torches (represented here as T) in a 3x3 grid, which is either a 3x1 or 1x3 line:
+-+-+-+ +-+-+-+
| | | | | |T| |
+-+-+-+ +-+-+-+
|T|T|T| or | |T| |
+-+-+-+ +-+-+-+
| | | | | |T| |
+-+-+-+ +-+-+-+
Then take the the ingredients and turn each one into a node. Traversing from the top left of the pattern to the bottom right, we insert each ingredient node a child of the previous (starting with a dummy root node).
[R]-[T]-[T]-[T]
We then finalise this pattern with a leaf node that encodes the dimensions of the recipe (ordered) to the resulting item (W is a torch wall and S is a super torch):
[1x3,S]
/
[R]-[T]-[T]-[T]
\
[3x1,W]
So now, when we query a pattern in the recipe tree, we just traverse from the top left to the bottom right of the pattern and determine if a child node exists for each recipe ingredient. If any are missing, there is no matching recipe. If we make it to a child node and there exists a leaf with matching dimensions then we have a matching recipe.
The beauty of this is that recipe nodes are shared between recipes that have common ingredients if their patterns overlapy. This ensures we use the minimum number of nodes to encode the recipes. Each leaf node stores only the dimensions and the result ingredient which is uniquely identifiable no matter if it is shaped or unshaped.
Jonathan Dickinson (what an absolute legend) was kind enough to grace our much undeserving selves with a fantastic illustration (that is not ASCII art, so actually readable) on the post that makes this a lot clearer of how shared nodes and dimensionality work:
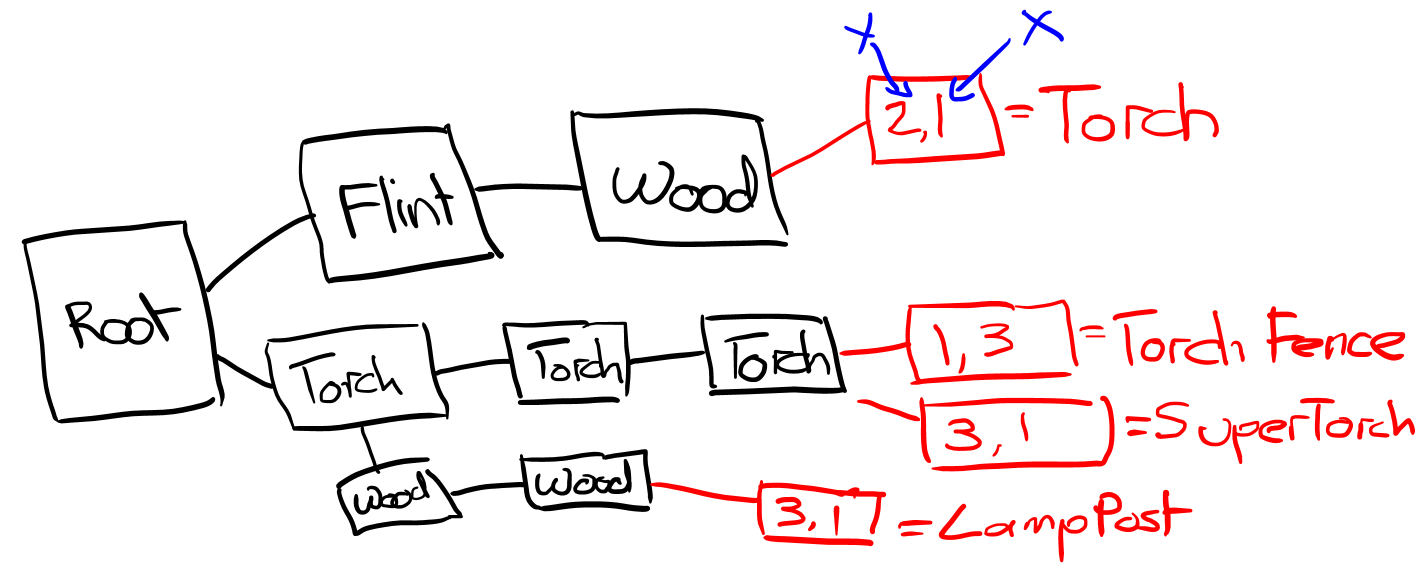
He also provides a fully fledged implementation of this in C# via GitHub. Later on, when detailing the full implementation in C, reference will be made to this, so it is worth checking out in advance for extra clarity.
Compile-Time Trees
Last on the list of requirements is compile-time representation of recipe patterns. Given that the approach that solved the other three requirements leans heavily on tree-based structuring, an arbitrary-depth compile-time tree would be ideal for this.
As per usual, this is a solved problem as well, courtesy of u/KJ7LNW's post Compime-time initialization of abitrary-depth tree-like structs on the r/C_programming subreddit and some input from u/jaskij's comment. The idea behind this is to create a single node definition that can store arbitrarily many child nodes (of the same type) wihtin it.
C Durations and Initialisation
C (and many other languages) have two main classifiers of when a value or layout is know at: runtime and compile time. These are determined by the storage duration of the value being initialised. Where objects with a static duration are declared either outside functions, or inside them with the keyword extern or static as part of the declaration. They can only be initialised at compile time [^1]: https://webhome.phy.duke.edu/~rgb/General/c_book/c_book/chapter6/initialization.html. All other declarations are considered runtime known durations and referred to as having automatic durations (with some exceptions where the storage and layout of the automatic duration object is compile-time know and the values are runtime known, though this is generally a compiler extension).
Compile-time initialisation is done via constant expressions, which is guaranteed to be fully known at compile-time, whereby the evaluated value could replace the expression and not change any program semantics. Modern C standards allow for simple values to be compile-time values as well as expressions (structs, arrays, enums, unions, etc) with some extra clauses on how they are declared and used.
Given the tree we want to utilise relies on structs and arrays (subseqeutlypointers) we need to pay attention to the rules for these.
Pointers
If we have an object that has a static storage duration or is a pointer to a function (that is known to the current compilation unit), then this is a valid compile-time value that is guaranteed to have a known position, alignment and thus address. From these we can take the address as a compile-time constant, known as an address constant (this includes NULL pointers and literal pointer integers). They behave identically to runtime know pointers in all ways. This allows for compile-time objects to referenced in other compile-time (or runtime) values.
void example(int value) {
println("Value was: %d\n", value);
}
typedef void (*ExampleFunc)(int);
// Address constant is a pointer to the function `example`
// which has a fixed location in the program at compile-time
// which does not change when loaded into memory. Thus is a
// valid constant value.
const ExampleFunc func = example;
const char* comptime_string = "test string";
// Valid address constant as `comptime_string` is known
// to have a fixed layout and memory location at compile
// time, initialised by a legal comptile-time value.
const char** comptime_string_ref = &comptime_string;Arrays
There are two main types of array initialisation that are legal at compile-time:
- Explicity sizes array with or without initialisers
- Explitictly sized leaf array of inferred sized parent arrays
In the first case we have trivially instantiable arrays that have all dimensions known at compile time. For example:
// This is strictly unsized
const char* string = "value"; // or { 'v', 'a', 'l', 'u', 'e', '\0' };
const char* array_1d[2];
// Auto-sizes to a size of 2 char pointers
const char* inline_array_1d[] = { "value1", "value2" };
const char* array_2d[2][1];For the second case, we could have nested arrays of arbitrary dimensions so long as the leaf array (at the tail end of declaration) is known at compile time.
const char* inline_array_2d[][1] = {
{ "arr1 val1" },
{ "arr2 val1" }
};Structs
Structures can be intiialised at compile-time if all of their members either either constant expressions of have values that are compile-time deducable. There are a lot of possible intialisation for structure members depending on their declarations and layout, so we will cull this down to only what we are interested in, other than trivially compile-time values.
Suppose the following structure definition, where we want to have a compile-time structure with arbitrarily many nested declarations of the same structure:
typedef struct Example {
int nested_count;
const struct Example** nested;
} Example;Given that the nested structures are arrays of pointers to structs, how do we go about instantiating this at compile-time? We can take advantage of the static addresses and for compile-time pointers as well as compile-time arrays. More specifically, if we can construct an array of nested objects that is known at compile-time, then the array's base address can be referenced for a static address to the array. Doing so guarantees that we have every aspect of the structure known at compile time:
const Example* nested[] = {
&(Example){
.nested_count = 0,
.nested = NULL
},
&(Example){
.nested_count = 0,
.nested = NULL
},
};
const Example example = (Example) {
.nested_count = 2,
.nested = nested,
};We can take this a step further and remove the const qualifer from the structure definition and inline the initialisation of the nested arrays:
const Example example = (Example) {
.nested_count = 2,
.nested = (Example*[]){
&(Example){
.nested_count = 0,
.nested = NULL
},
&(Example){
.nested_count = 0,
.nested = NULL
},
},
};Now it's starting to look like a tree!
Constructing Recipe Trees
Now that we have covered the C concepts necessary to build trees at compile-time, as well as the structuring approach for recipes themselves, we can dive into the full compile-time recipe tree approach. First, let's start with constructing a recipe node that represents an ingredient in the tree of patterns. We will do so in the format of the nested struct layout we defined in the previous section.
typedef struct RecipeNode {
/**
* @brief Recipe item ingredient for this position.
* marked by id and metadata id
*/
CompositeID item;
u16 stack_size;
/**
* @brief Number of elements in `nodes`
*/
u8 node_count;
/**
* @brief Number of elements in `results`
*/
u8 result_count;
/**
* @brief Contains the result of the recipe taking the items in the
* the tree up until this node. This should be null when
* `result_count`is `NULL`endcode. Otherwise the number of
* elements in this array should be equal to `result_count`
*/
RecipeResults** results;
/**
* @brief Next items in the recipe, ordered by item IDs. Note
* that this should be null when @code node_count@endcode
* is `NULL`. Otherwise the number of elements in this
* array should be equal to `node_count`
*/
struct RecipeNode** nodes;
} RecipeNode;These nodes store a single item by it's ID and metadata ID, represented here as the CompositeID type (which we will come back to later). All other fields are essentially tree representation data. A can contain any number of children via the nodes sized by the node_count field. These child nodes are arrays of of the node struct layout. The results field here contains an array of dimensionally unique results for the given pattern as there may be multiple ways to orient the same recipe (i.e vertically or horizontally). Each of these results are matched against the input pattern to find a match.
typedef struct Dimension {
u8 width;
u8 height;
} Dimension;
typedef struct RecipeResult {
/**
* @brief Recipe item ingredient for this position.
* marked by id and metadata id
*/
CompositeID item;
u16 stack_size;
} RecipeResult;
typedef struct RecipeResults {
/**
* @brief Dimensions of the recipe in a crafting grid, the items in
* the tree as parents to this result node are positioned in
* the grid from the top left to bottom right. This allows the
* recipe to be positioned anywhere and only be constrained to
* the pattern itself.
*/
Dimension dimension;
u32 result_count;
RecipeResult** results;
} RecipeResults;Taking a look at the RecipeResults structure, we can see they are characterised by the results field is an array of results for each output slot the recipe returns results to. This allows for the recipe tree to be used for multi-output recipes (i.e. machines) as well as single output like crafting tables. The dimension field encodes the layout of the nodes based on the width and height of the quadralateral hull of the pattern.
NOTE:
As an side the 16-bit stack-size variable is probably overkill but it lends nicely to ensuring that theRecipeResultstruct layout is packed well with no extra padding becauseCompositeIDis also 16-bit. This is a trade-off made to ensure the layout efficiency of the tree and also maximise usability, but that may vary if you need very large stack sizes, exceeding 65,535.PSXMC actually only uses 8-bit unsigned integers for stack sizes on items, maxing out the stack sizes to 255, so realistically I could drop this to a
u8with anotheru8of padding, but it makes this write-up a bit more convoluted to look at with the struct definitions.
Lastly, let's take a look at the CompositeID definition.
typedef union CompositeID {
struct {
// Lower bits
u8 metadata;
// Higher bits
EItemID id;
} separated;
u16 data;
} CompositeID;Initially, it may seem strange that we have a union representation of the ID and metadata IDs, but if we take a step back and consider what needs to happen during a traversal of this tree when querying, it becomes much clearer as to why. When a pattern is being queried, we walk the tree searching for child nodes at each level that much the current item in the pattern we are looking for a match on. There may be quite a few child nodes in the nodes array of a RecipeNode instance, and a linear search seems like a generally bad approach for anything other than a few elements. At the same time we don't want an expensive array traversal algorithm because it is unlikely that there will be many child nodes. So a binary search is a nice middle ground, and also easy to implement.
An item is uniquely definined by firstly it's ID between distinct items, and secondarily by it's metadata ID as variants of the same item. A naive solution would be to have nested arrays of reults based on ID and them metadata ID within and binary search both times, however, given one is a subset of the other, we can instead merge the two into one value, where we guarantee that the item ID is stricly larger (in each step) than all the valid metadata IDs that denote variants of it. As such if we use the upper half of a 16-bit integer for the item ID and then the lower 8-bits as the metadata ID, we can indeed guarantee this property. When we do a binary search over this composite value, we can guarantee that by traversing left or right of the current value, we first stricly increase or decrease the metadata ID, and then the main item ID:
[ ID: 1 ] [ ID: 2 ]
[M-ID: 0] [M-ID: 1] [M-ID: 0]Is the same as
[ID: 1 M-ID: 0] [ID: 1 M-ID: 1] [ID: 2 M-ID: 0]Thus the CompositeID is born and binary search is trivially implementable just using integer comparison of the data field of the union which is the whole 16-bit integer.
RecipeNode* recipeNodeGetNext(const RecipeNode* node, const RecipePatternEntry* pattern) {
if (node->nodes == NULL || node->node_count == 0) {
return NULL;
}
// NOTE: These need to be signed otherwise we can get upper to
// be u32::MAX if there is only one element in the array
// and it doesn't match the item
i32 lower = 0;
i32 mid;
i32 upper = node->node_count - 1;
while (lower <= upper) {
mid = (lower + upper) >> 1;
RecipeNode* next_node = node->nodes[mid];
if (next_node->item.data == pattern->id.data) {
if (next_node->stack_size < pattern->stack_size) {
// Number of items in the slot is insufficient
return NULL;
}
return next_node;
} else if (next_node->item.data > pattern->id.data) {
upper = mid - 1;
} else {
lower = mid + 1;
}
}
return NULL;
}
Support Macros and Tree Definitions
When we cosntruct a tree the type definitions are required to be explicit as compilers tend to deduce the incorrect types or necessitate explicit types when it comes to the compile-time array declarations. As such three sets of support macros exist to make the tree definition process much simpler:
#define RECIPE_LIST (RecipeNode*[])
#define RECIPE_ITEM &(RecipeNode)
#define RECIPE_RESULTS_LIST (RecipeResults*[])
#define RECIPE_RESULTS_ITEM &(RecipeResults)
#define RECIPE_RESULT_LIST (RecipeResult*[])
#define RECIPE_RESULT_ITEM &(RecipeResult)
#define RECIPE_COMPOSITE_ID(_id, _metadata) { \
.separated.metadata = _metadata, \
.separated.id = _id \
}This means that a simple tree can be defined via tokens and brace initialisation very easily:
const RecipeNode tree = RECIPE_ITEM {
.item = RECIPE_COMPOSITE_ID(0, 0),
.stack_size = 0,
.result_count = 0,
.node_count = 1,
.results = NULL,
.nodes = RECIPE_LIST {
[0]=RECIPE_ITEM {
.item = RECIPE_COMPOSITE_ID(5, 2),
.stack_size = 1,
.result_count = 1,
.node_count = 0,
.results = RECIPE_RESULTS_LIST {
[0]=RECIPE_RESULTS_ITEM {
.dimension = { .width = 1, .height = 1, },
.result_count = 1,
.results = RECIPE_RESULT_LIST {
[0]=RECIPE_RESULT_ITEM {
.item = RECIPE_COMPOSITE_ID(12, 0),
.stack_size = 4,
},
},
},
},
.nodes = NULL,
},
},
};Querying a Pattern
Lastly, let's go over how you actually query a tree and the decisions made therein for better integeration with a block that has crafting mechanics. The initial section to consider the format of the query to submit/use when traversing the tree. When we think about it, there are really only two main components; a representation of the pattern currently in the recipe and the slots to store the results into, which are potentially already occupied.
typedef struct RecipePatternEntry {
CompositeID id;
u8 stack_size;
u8 _pad;
} RecipePatternEntry;
typedef RecipePatternEntry* RecipePattern;
#define RECIPE_PATTERN(name, count) RecipePatternEntry name[(count)]Each entry of the pattern is denoted by the composite ID of the item and the stack size, which can be saturated with the item stack details for each input slot. Using the RECIPE_PATTERN macro allows for a pattern to be defined according to the number of inputs that are present. For example, a crafting grid 3x3 with 9 inputs or a machine with 4x2 input slots for 8 total. Let's consider what occurs when we want to walk the recipe tree for an example pattern:
+-+-+-+
| | | |
+-+-+-+
| |T|T|
+-+-+-+
| |T|T|
+-+-+-+
Since the 3x3 pattern here is represented with a 1D array of 9 elements, we would need many redundant nodes in the tree if we walked from the start to end of that pattern trying to match child nodes for each pattern element. Especially since theres lots of empty space we don't really need to care about. This is essentially the problem of generalising shaped crafting that only takes a subset of the input slots. So, we can provide dimensions for the input slots in order to compute the quadralateral hull of the pattern with actual elements in it. For our example, that would mean we only consider the bottom right four elements of the grid. more generally, this looks like:
u8 right = 0;
u8 bottom = 0;
u8 top = pattern_dimension.height;
u8 left = pattern_dimension.width;
// Compute the quaderlateral hull of the pattern slots
// that have items in them. This is the subset of the
// pattern that is used to walk the tree.
for (u8 y = 0; y < pattern_dimension.height; y++) {
for (u8 x = 0; x < pattern_dimension.width; x++) {
if (pattern[(y * pattern_dimension.width) + x].id.separated.id != ITEMID_AIR) {
left = min(left, x);
top = min(top, y);
right = max(right, x);
bottom = max(bottom, y);
}
}
}With the resulting bounds of right, bottom, top and left, we can now walk the tree with only the hulled elements. I'll leave it as an excersise to the reader to convice yourself that this works for constructing a quad hull with non-square pattern subsets (i.e an L shape in the same position in the 3x3 yeilds the same hull as a 2x2). Now, walking the tree is simply a matter of traversing each of the pattern elements in the hull in order:
RecipeNode const* current = root;
for (u8 y = top; y <= bottom; y++) {
for (u8 x = left; x <= right; x++) {
const u32 index = (y * pattern_dimension.width) + x;
current = recipeNodeGetNext(current, &pattern[index]);
if (current == NULL) {
return RECIPE_NOT_FOUND;
}
ingredient_consume_sizes[index] = current->stack_size;
}
}Note the introduction of the ingredient_consume_sizes which is just an array of u8 to store the stack size required for the item at the pattern index for the current ingredient, so that we know how much to consume from the item stack later when actually taking the result item(s). Either we terminate the loop early an indicate that a recipe is not found in the case that we couldn't find a matching recipe node or the current variable contains the last recipe node, inidcating a matching recipe. At this point we can find the result node in current->results that has matching dimensions with our subset of the pattern and construct the results appropriately, or return nothing to indicate that there was a dimension mismatch.
RecipeQueryState recipeNodeGetRecipeResult(const RecipeNode* node,
const Dimension* dimension,
RecipeQueryResult* query_result,
bool create_result_item) {
if (node->results == NULL || node->result_count == 0) {
return RECIPE_NOT_FOUND;
}
for (u32 i = 0; i < node->result_count; i++) {
RecipeResults* result = node->results[i];
if (dimensionEquals(dimension, &result->dimension)) {
if (create_result_item) assembleResult(result, query_result);
return RECIPE_FOUND;
}
}
return RECIPE_NOT_FOUND;
}I won't go into details on the assembleResult method too much as it is just item construction code for each result element and logic for handling overlap with items already in the result slots. However, one thing here that is worth addressing is the create_result_item flag, which dicates whether to do this action or not. The reasoning here is we may only want to actually create results when an action different to the one that started the query occurs. I.e. putting items into the input slots will attempt to resolve the results to validate it and only when a button is pressed the recipe is actually processed.
Traversing Nodes
Let's go back a bit to the recipeNodeGetNext function that was in the code for traversing the tree based on the pattern subset:
RecipeNode* recipeNodeGetNext(const RecipeNode* node, const RecipePatternEntry* pattern) {
if (node->nodes == NULL || node->node_count == 0) {
return NULL;
}
// NOTE: These need to be signed otherwise we can get upper to
// be u32::MAX if there is only one element in the array and it
// doesn't match the item
i32 lower = 0;
i32 mid;
i32 upper = node->node_count - 1;
while (lower <= upper) {
mid = (lower + upper) >> 1;
RecipeNode* next_node = node->nodes[mid];
if (next_node->item.data == pattern->id.data) {
if (next_node->stack_size < pattern->stack_size) {
// Number of items in the slot is insufficient
return NULL;
}
return next_node;
} else if (next_node->item.data > pattern->id.data) {
upper = mid - 1;
} else {
lower = mid + 1;
}
}
return NULL;
}This is the same function that was mention during the explanation of the CompositeID and why it exists. The only difference here is that we account for the stack size as a constibution to determining the validity of a node as a match for a pattern element. Even if the items match ID-wise, if we don't have enough items in the input slots, then the pattern cannot be a match.
It should be noted that this function relies on the nodes to be pre-sorted based on their composite ID, which in PSXMC is done via a script that preprocesses a JSON definition of the recipes into a recipe tree definition as a source and header combination. If you are constructing these manually and using this function, then you should be aware of this otherwise you'll get some wild results.
Deferred Ingredient Consumption
Previously, it was mentioned that the traversal code for querying a recipe would saturate an array of u8 that stores the stack sizes of each recipe ingredient. This exists as a means to know how much of an item stack in each input slot for the pattern should be consumed when the recipe is processed. To make this easier, a utility function exists in the PSXMC implementation to do this specifically:
void recipeConsumeIngredients(Slot* slots,
const u8* ingredient_consume_sizes,
int start_index,
int end_index) {
for (int i = start_index; i < end_index; i++) {
Slot* slot = &slots[i];
IItem* iitem = slot->data.item;
if (iitem == NULL) {
continue;
}
Item* item = VCAST_PTR(Item*, iitem);
assert(item->stack_size > 0);
item->stack_size -= ingredient_consume_sizes[i];
if (item->stack_size == 0) {
VCALL(*iitem, destroy);
slot->data.item = NULL;
}
}
}This allows you to this consumption easily, with a few assumptions built in here about the stack sizes already being validated as at least large enough to remove the items from prior to invoking the function. It is generally applicable though a quality-of-life function that any usage of the recipe handlers can take advantage of such a crafting tables, inventory crafting, furnaces, modded machines, etc.
Conclusion
Hopefully, this did decent job at explaining how/why the recipe system is implemented in PSXMC in this way. There's a lot to consider performance wise as a tradeoff for your needs though as it can make the API for recipe handlers a bit cumbersome, which you could argue is the case with PSXMC. However, for the sake of limited resources and adaptability this seems to get the job done. The following parts of the PSXMC repository might be helpful as additional resources if you wish to see the full implementation and usage:
- Recipe API: src/game/recipe/recipe.h src/game/recipe/recipe.c
- Crafting table usage: src/game/blocks/block_crafting_table.c
- Inventory usage: src/game/gui/inventory.c
- Crafing recipe tree (only some recipes): src/game/recipe/crafting.c
- Utility script to parse JSON definition to a recipe tree (currently missing handling for stack sizes): scripts/recipe_tree.py